Entre las tareas que pueden denominarse comunes en un proyecto de BI es la construcción de un datamart o datawarehouse, y las tablas hechos pueden contener un volumen considerable como para hacer inserciones de filas una por una.
¿De qué forma podemos optimizar las inserciones de estas filas sin evitar que se realice el chequeo de restricciones tales como una clave principal?... Si intentamos introducir en la tabla una clave duplicada genera una fila de error en el componente que podemos capturar y procesar.
Teniendo esto en cuenta, la solución pasa por añadir más destinos y anidarlos, conectando al siguiente componente destino la salida de error del anterior.
La siguiente imagen es una muestra de cómo conectar los destinos de mayor a menor tamaño de lotes:

Mediante esta metodología intentamos introducir grandes lotes de filas y en caso de que alguna genere un error, pasa a un tratamiento más "fino", hasta llegar a la inserción de una fila por lote.
Lo único que hay que hacer es cambiar la configuración de nuestro componente OLEDB Destination modificando los siguientes parámetros:
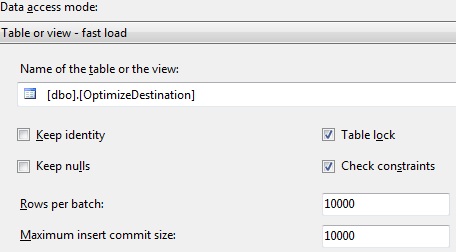
En la siguientes capturas se puede apreciar la diferencia de tiempo que hay en la ejecución de un paquete con filas duplicadas en destino y las distintas formas de realizar la inserción:
Fila por fila:




Una significativa diferencia de 2'5 minutos en el proceso de inserción en un destino donde existen el 25% de las filas.
Existen formas más efectivas de eliminar las filas del flujo de datos que ya existan en la tabla destino. El método a utilizar depende de la cantidad de datos que se vaya a manejar.





No hay comentarios:
Publicar un comentario